Even More Memory
6 Jun 2013
I did say memory was an important part of what the operating system does. Here's another post on it.
Forking a process
By using a system call a process may fork i.e. create a copy of itself.
Right after the fork, the entire memory space should look the same to both the parent and child. However, if one changes something, the change should not affect the other.
For example:
#include <stdio.h> #include <unistd.h> #include <sys/wait.h> int main(int argc, char **argv) { int variable = 1; int pid = fork(); int status; if( pid ) { // This is the parent printf("Parent says: %d\n", variable); variable = 2; printf("Parent says: %d\n", variable); waitpid(pid, &status, 0); // Let the child run printf("Parent says: %d\n", variable); } else { // This is the child printf("Child says: %d\n", variable); variable = 3; printf("Child says: %d\n", variable); } return 0; }
This simple program should output (assuming the parent is run first and is not interrupted):
Parent says: 1 Parent says: 2 Child says: 1 Child says: 3 Parent says: 2
The virtual memory of the X86 architecture allows us to switch out the entire memory space in one strike, and that allows for this behavior.
The naive way to implement this functionality is to make a copy of the
entire memory space, page for page, during the fork and assign it to the
child process. However, it is common for a new process to start its life
by performing execve() or similar and thus clearing or replacing its
entire memory space. Obviously this would make copying the memory space
just a waste of time.
A way to prevent this waste is to make all points on the two processes memory maps point to the same physical memory as long as they only read. A copy is made only if either process wishes to write to a memory area. This method is known as Copy on Write.
Now, I never took any courses in data structures and I'm sure there's better ways of doing this, but here's how I keep track of the memory areas used and shared between processes.
Process memory map
In the kernel, each process has an associated memory map. The memory map contains information about the memory areas of the process.
Each memory area describes a part of the process' memory. The size of
the part can go from 0 to the entire memory space. The memory area
structure thus has one field for the starting address of the area and
one for the end address. It also has a field describing the area type
and a flags field.
Each memory area belong in two doubly linked lists. One is the list of memory areas belonging to a process. The other list is all copies of the area.
Finally, each area has a pointer to its owning process.
Let's follow a memory area during part of a process' life.
Setup
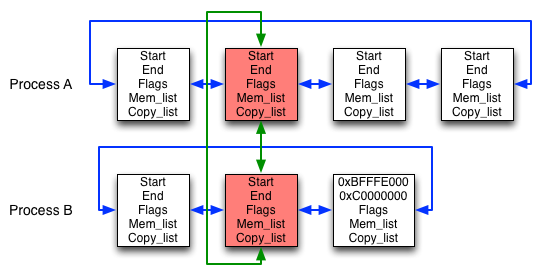
In the figure above we see two processes, A and B. Let's say A is the init process and B is a shell.
Currently, A has four memory areas and B has three. As you can see, all the processes memory areas are linked together in a list (blue arrows). A and B also share one area and the two representations are linked together in another list (green arrows). The shared areas are flagged as "Copy on Write" (red color).
We'll be following the rightmost memory area of process B. This area
represents the stack and stretches from 0xBFFFE000 to 0xC0000000.
In other words, it is two memory pages long (assuming 4kb pages).
Forking
The user types
$ gcc hello_world.c
into the terminal and the shell program executes the fork system call.
This makes the kernel do a lot of things, one of which is create a new memory map for the new process. It then clones all memory areas into the new map.

The write flag of our area is unset and the CoW flag is set. The area is then copied into the new map and the copies list is updated so that our area and its copy can keep track of each other.
Pushing to stack
Let's say the scheduler returns us to the child process (process C) when the fork is complete.
The child process does some processing on the user entered command and during this tries to write a value to the stack. Since the area containing the stack is read-only this results in a page fault.
The page fault handler recognizes that the fault was caused by an attempt to write to a read-only page and by a quick check finds out that the area in question is marked for CoW, so it decides to make a copy of it. There's no need to copy both pages, though, so the memory manager first splits the area in two.
The same split is made in all copies of the same area. Finally, the area we want is physically copied and write is enabled on it before control is returned to the user process.
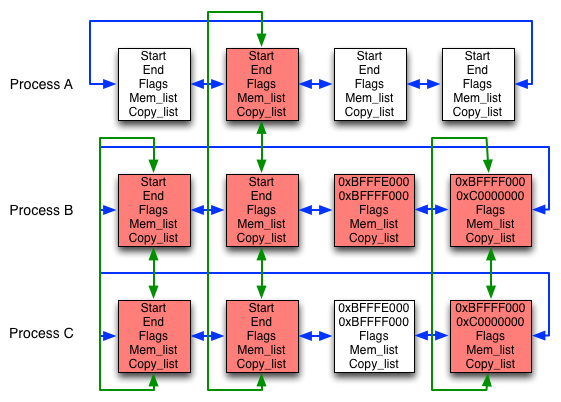
A while later, the parent process is scheduled in and it may also wish to write to the stack. This time the area is already split in two, and the required area has no copies, so it is just set as read/write and we're done.
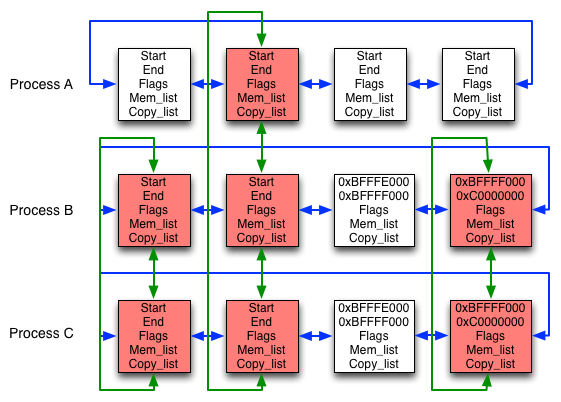
Actually, the parent process will probably perform a waitpid syscall
and sleep untill the child has finished, so let's go back to the child.
Exiting
When the child process finishes, it frees all memory areas. When a page marked CoW is requested, the first check performed by the kernel is wether there actually are any other processes sharing the same area. Otherwise, it just marks it as read/write and is done. Therefore, all the child process needs to do is remove its own memory areas from the list of copies and the parent will take care of the rest.
Zero size areas
I said before that an area could have a zero size, i.e. the same start and end address.
This is only useful in combination with a certain flag that allows the area to grow automatically.
It could for example be used by a stack area which might originally
start at 0xC0000000 and end at 0xC0000000. If an uint32_t is
pushed, the process will try to write to address 0xBFFFFFFC which
results in a page fault.
The page fault handler will realize that theres a memory area right above the address (say less than one page away) and that this area has the autogrow flag enabled. It will then just expand the area and be done.
The pros of this method is that we will never have to guess how large the stack size should be. It will grow as neede (to an extent) or stay at zero size if it's not needed.
Git
The methods described in this post has been implemented in git commit cea5ec765f.